Table of Contents
On Hangul Supremacy & Exclusivity – An Information Theory Comparison of Hangul and Hanja

An Information Theory Comparison of Hangul and Hanja
“A picture is worth a thousand words.” This is a well-known English proverb. Most do not think about why this proverb is true, because its proof seems quite obvious. If one were to describe a picture in words, he would need indeed a lot of words. Why is that so? The answer can be found in information theory, a field of study that has made modern digital communications possible and plays an important role in several other fields including linguistics.
A Layman’s Short Introduction to Information Theory
Information theory involves the quantification of “information.” Information should be distinguished from semantic meanings. Messages and symbols therein often have meaning referring to some system of physical or abstract things. Information theory does not care what these symbols actually mean. This is not to say that information has no relevance to meaning; messages tend to communicate meaning and have information. Information is concerned with each symbol’s probability of being observed; it is concerned with reduction in uncertainty in observing each symbol.
Illustrative Examples
Information thus depends on the distribution of the symbols, or elements, that are in one set of symbols. In general, the higher the number of elements, the higher the information. For instance, imagine observing a coin toss and a fair die roll. The probability of heads and tails of the fair coin is 1/2 each. The probability of each side of the die is 1/6 each. Comparatively, there is more uncertainty in the outcome of the die roll than the outcome of a coin flip. When the actual outcome is observed, the uncertainty in each observation is reduced to zero. Since more uncertainty was reduced in the fair die roll, there was more information provided by the outcome of the die roll than the coin flip.
Thus, it can be easily seen why the proverb “a picture is worth a thousand words” is true. A picture is effectively a set with an infinite number of symbols, each symbol with an infinitesimal probability of being observed, regardless of how each symbol is defined. On the other hand, words are effectively a set with a finite number of symbols. To get a empirical sense, approximately 10,000 words comprise the vocabulary of native speakers with higher education. The word set is thus far smaller than the picture set. Therefore, observing a picture reduces uncertainty much more than observing words, and a coin flip and die roll.
Measuring Information
Mathematically, assuming that each symbol is independent, the information of a symbol is:
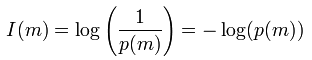
where I(m) is the information of a symbol and p(m) is the probability of observing symbol m. For a number of reasons, it is a logarithmic measure. Principally, it is close to the intuitive sense of a measure of information: that is, the amount of information increases at a slower rate than the increase of symbols in a set. The unit for information is typically bits-per-symbol, because computers use binary numbers (i.e., 1s and 0s) and most applications of information theory involve digital communication using computers.
The average information for a set of symbols is called entropy. Mathematically, entropy is:
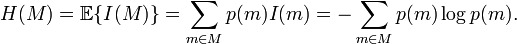
where H(M) is the entropy measured in bits-per-symbol, M is the total set of symbols, and p(m) is the probability of observing symbol m. There are a number of ways to interpret what entropy is. One is the average amount of information provided by the distribution of the set of symbols. From this interpretation, the higher the entropy, the higher the average information for that set of symbols. It should be noted that the average information of a set is the highest, when all the symbols have an equal probability of being observed. This is also when the entropy of the entire set equals the information of each symbol.
Comparing the Information Hangul Versus Hanja
According to information theory, Hangul should have a lower amount of average information than Hanja. Hangul is a phonetic alphabet comprising of only 24 symbols. Hanja, in contrast, is an ideogram comprising of more than 40,000 symbols, out of which only about 2,000 are considered “common use” in Korea. From the start, it can be readily recognized that there is a lot more uncertainty in observing a Hanja character versus observing a Hangul letter.
To get a sense of the disparity, assume that each symbol in each respective script occurs with equal probability and is independent. That is, each alphabet of Hangul occurs 1/24 of the time and each character in Hanja occurs 1/2000 of the time. (The actual probability for Hangul ranges from 0.122 for ㅇ and 0.002 for ㅋ. This blogger has not yet found a complete listing for Hanja). Thus, the entropy of Hangul is only 4.75 bits-per-symbol, while the entropy of Hanja is 10.96 bits-per-symbol — and 15.29 bits-per-symbol, when 40,000 symbols are considered. This means that each character of Hanja conveys much more information than each alphabet of Hangul.
Of course, this assumption that each symbol in each respective script occurs with equal probability is not entirely correct. Certain symbols do occur with more frequency than others, and therefore the entropy in actuality will be much lower. This, however, does not detract away from the finding that each character of Hanja conveys more information than each letter of Hangul: there is still a lot more Hanja characters than Hangul letters. The fact that Hanja conveys more information than Hangul has ramifications in the semantic meaning conveyed by each symbol.
For example, take the Hangul letters “일.” It has three symbols: ㅇ, ㅣ, and ㄹ. Even with three symbols, the semantic meaning is highly ambiguous. It could mean “one,” “work,” “day,” or even a grammatical particle. Contrast this to seeing just one Hanja character. Since there is a lot more information, the characters 一 (one), 業 (work), and 日 (day) are less ambiguous. Consider also the following examples, comparing one Hanja character with the number of Hangul letters required to transmit the same semantic meaning:
- 車(1) → 차(3) (“car”)
- 天(1) → 천(3), 하늘(5) (“sky”)
- 止(1) → 지(2), 멈추다(7) (“to stop”)
- 褰(1) → 건(3), 옷을걷어올리다(18) (“to hang up clothes”)
- 蔭(1) → 음(3), 조상의 공덕에 의하여 맡은 벼슬 (33) (“A bureaucratic position attained based on merits of an ancestor”)
This finding should not be surprising. In no instance, can the representation in Hangul be more compact than the representation in Hanja. Since Hanja characters have a higher amount of information, more Hangul letters are necessary to convey the same amount of information — and incidentally the same meaning. (One can also see this is the case with Morse code versus English).
This is more apparent with prose text. Compare the original Classical Chinese text of the Pater Noster (天主經, 천주경) versus the Hangul-only Korean translation (both are Catholic translations):

Notice how few the number of symbols are in the Classical Chinese text is compared to how many Hangul letters are in the Hangul-only Korean translation. Both are roughly the same symbolic representations of the underlying semantic meaning. Hangul only appears more compact, simply because of its arrangement into syllable blocks. Other comparisons of Classical Chinese text and mixed script versus Hangul-only representations will show the same result, without fail. Hangul is vastly inferior from an information theory perspective.
Conclusion
This blogger conceived of this argument, to introduce much needed objectivity the debate between Hangul exclusivity and mixed script. In the end, subjective arguments, such as appeals to nationalism, history, aesthetics, and et cetera, amount to mere sentiment. The “superiority” of a script is not one dimensional; there are a number of measures. Ease of learning is one measure, albeit very subjective. The amount of information conveyed is another. The latter is perhaps more significant and objective measure, because the most important function of any script is to convey meaning. There is also the issue of transcribing meanings not represent-able in Hanja versus Hangul. A mixed script with an optimal distribution of probability between the two scripts would actually increase the information content, shortening the amount of symbols needed to convey the same meaning while maintaining ease of learning.
Disclosure: This blogger has had his acquaintances, who are far better versed in information theory than he is, verify the argument in this blog post.